



En tekniskt väloptimerad webbplats är viktig av två skäl: Det ena är synlighet i sökresultaten och det andra är användarupplevelsen. Dessa faktorer samspelar, eftersom användarsignaler har viss betydelse för rankningen av sökresultaten. Även om teknisk optimering inte på något sätt garanterar topplaceringar vill man som minst eliminera alla potentiella hinder och underlätta för Google att indexera sajten.
Här tittar vi närmare på vad teknisk SEO är, hur du genomför en teknisk SEO-analys och vilka optimeringar som är viktigast att prioritera.
Innehåll
ToggleVad är teknisk SEO och varför är det viktigt?
- Indexering och "crawlbarhet" – Crawlability; hur enkelt Google kan genomsöka sajten
- Webbplatsens laddningstider – Olika aspekter av Googles Core Web Vitals
- Struktur och hierarki – Navigering, URL-struktur, breadcrumbs m.m.
- Mobilanpassning – Likvärdig upplevelse på alla typer av skärmar
- Säkerhet – Hantering av SSL-certifikat (HTTPS)
- Kodstruktur och felhantering – Javascript, strukturerad data 404-sidor, redirects
Delar av den här terminologin låter kanske inte särskilt nybörjarvänlig, men blir förhoppningsvis mer begriplig strax. Först är det dock viktigt att du har viss förståelse för hur Google och sökroboten Googlebot fungerar.
Hur Googlebot Fungerar

Googlebot är Googles automatiserade webbcrawler, som kontinuerligt genomsöker webben för att upptäcka och indexera webbsidor. Det är den primära mekanismen för Google att samla in information om webbsidor för att sedan avgöra vilka sidor som ska visas i sökresultaten. Även andra sökmotorer har motsvarande crawlers, t.ex. Bings Bingbot. LLM:er som ChatGPT fungerar lite annorlunda, men har samma behov av enkel tillgång till webbsidors innehåll.
Så här går processen till på en övergripande nivå:
1. Upptäckt av URL:er (sidor)
För att hitta nya sidor på webben använder Googlebot några olika metoder:
- Länkar från redan indexerade sidor (den vanligaste metoden)
- XML-sitemaps som skickas via Google Search Console
- Direkta URL-förfrågningar via Search Console
- Externa länkar från andra webbplatser
2. Crawl-prioritering
- Crawl-budget - Hur stora resurser Google allokerar till din webbplats
- Domänens länkprofil (PageRank) - Etablerade sajter får mer resurser
- Uppdateringsfrekvens - Sidor som uppdateras ofta får högre prioritet
- Robots.txt-direktiv och meta-taggar
Googlebot undviker att indexera och bearbeta sidor om du uttryckligen inte vill att de ska indexeras. Du kan specificera sådana med filen robots.txt, meta robots-taggar eller X-Robots-Tag. Det kan vara användbart för exempelvis användargenererat innehåll och inloggade funktioner.
3. Rendering och bearbetning
- Laddar HTML-koden först
- Kör JavaScript (med vissa begränsningar)
- Renderar sidan för att se slutresultatet
- Analyserar innehåll inklusive text, bilder, länkar och metadata
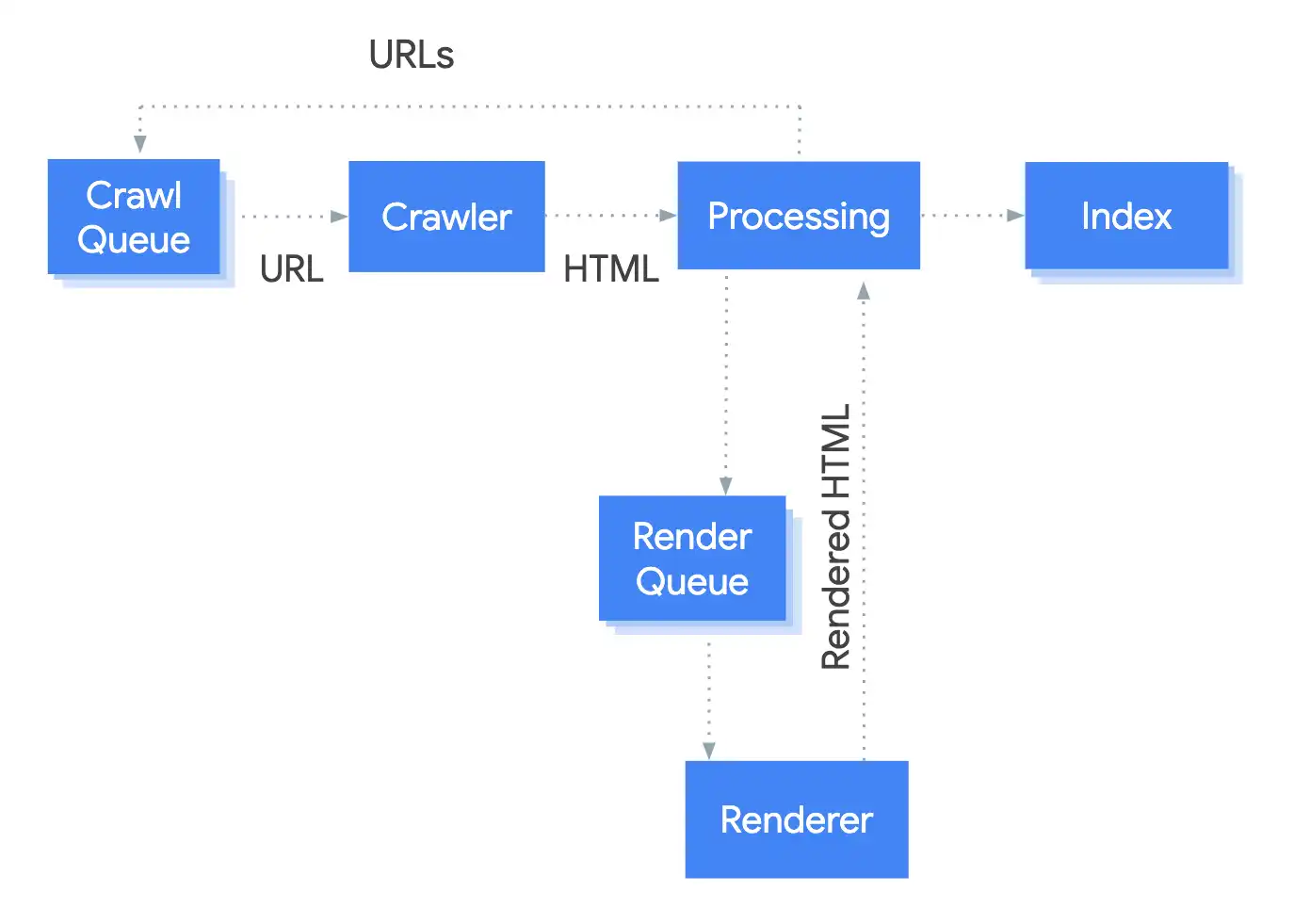
Faktorer som påverkar crawling
De viktigaste tekniska förutsättningarna för att Googlebot ska kunna crawla effektivt är laddnings- och svarstider, webbplatsens struktur (djup länkstruktur kan försvåra), internlänkning, samt förstås rena fel som trasiga länkar och JavaScript-problem.
Eftersom crawling av en webbplats sker inom ramen för en individuell crawl-budget är det viktigt att det sker så effektivt som möjligt.
Skapa sitemap.xml och konfigurera robots.txt
Exempel: Skapa sitemap i WordPress
En sitemap.xml är enkelt uttryckt en lista över alla sidor på din webbplats som du vill att sökmotorerna ska indexera. Den fungerar som en karta över webbplatsen, vilket gör det enklare för sökmotorer att förstå hur sidorna hänger ihop och vilka som ska prioriteras.
Om du inte har en helt statisk sajt vill du som regel att sitemap.xml uppdateras och hålls aktuell automatiskt. I WordPress hanteras det enklast med plugins som Yoast.
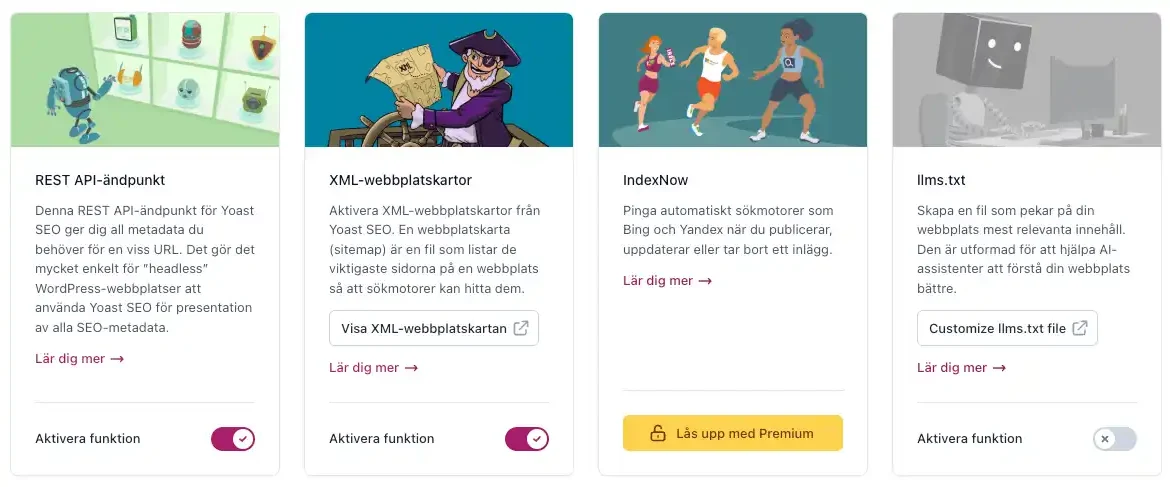
Yoast SEO (och många liknande plugins) genererar automatiskt en dynamisk sitemap som finns på dinwebbplats.se/sitemap_index.xml. Det skapar separata sitemaps för olika innehållstyper som inlägg, sidor och kategorier.
Andra CMS-plattformar som Shopify, Wix med flera har oftast inbyggda funktioner eller motsvarande tillägg för att generera sitemaps. Du kan även använda verktyg som Screaming Frog för att generera en sitemap manuellt.
Så fungerar robots.txt
Robots.txt är en väldigt simpel textfil som kontrollerar vilka delar av din webbplats sökmotorernas robotar får tillgång till. Denna fil måste placeras i rotmappen på din webbplats (t.ex. https://www.exempel.se/robots.txt) för att sökmotorer ska kunna hitta den.
För att skapa en robots.txt-fil behöver du:
- Öppna en textredigerare (som Notepad eller liknande)
- Skapa en ny fil och spara den som ”robots.txt” (använd små bokstäver)
- Ladda upp filen till webbplatsens rotmapp
Den grundläggande syntaxen för robots.txt inkluderar:
User-agent: [sökrobot]
Disallow: [mapp eller fil]
Allow: [mapp eller fil]
Där:
- User-agent specificerar vilken sökrobot regeln gäller för. Använd asterisk (*) för alla robotar.
- Disallow talar om för roboten vilka mappar eller filer den inte ska besöka.
- Allow ger tillgång till specifika sidor inom en blockerad mapp.
Exempel på en enkel robots.txt-fil:
User-agent: *
Disallow: /privat/
Allow: /privat/offentlig-sida.html
Detta blockerar alla sökmotorer från att besöka mappen ”privat” men tillåter åtkomst till sidan ”offentlig-sida.html” inom den mappen.
Hur du länkar till sitemap i robots.txt
Du kan också lägga in en referens till XML-sitemap i robots.txt-filen för att förenkla för robotar.
Använd följande format:
Sitemap: https://www.dinwebbplats.se/sitemap.xml
Du kan även lägga till flera sitemaps:
Sitemap: https://www.dinwebbplats.se/sitemap-sidor.xml
Sitemap: https://www.dinwebbplats.se/sitemap-inlagg.xml
Sitemap-direktivet är oberoende av User-agent-linjen och kan placeras var som helst i robots.txt-filen. Tänk på att URL:en måste vara fullständig (absolut, inklusive protokoll och värdnamn) och är skiftlägeskänslig.
Du kan testa robots.txt-filen i Search Console när du är klar.
Optimera struktur och interna länkar
Navigering och interna länkar kan vara minst lika viktiga som externa länkar. De fungerar som vägledning för både besökare och sökmotorer.

Mest effektiv är en logisk hierarki där innehållet är organiserat i tydliga kategorier och underkategorier som hjälper användare att hitta och Googlebot att indexera.
Tänk på att du aldrig ska ändra URL-struktur för sidor som redan är indexerade och rankar. I så fall är det viktigt att använda 301-redirects.
Om du startar från ruta ett är det däremot klokt att redan från start organisera innehållet i huvudkategorier och underkategorier som speglar din verksamhet. Ett typexempel för e-handel är: /produktkategori/produkt/
Håll gärna strukturen enkel med högst tre nivåer i din hierarki (huvudkategorier, underkategorier och enskilda sidor). Alla viktiga sidor bör vara länkade från från huvudmenyn eller andra delar av webbplatsen,
Undvik orphan pages
”Orphan pages” eller föräldralösa sidor är sidor som saknar interna länkar från andra delar av sajten. De kan i undantagsfall hittas av Googlebot, men får ingen styrka från länkar och kan inte hittas alls av användare som inte kan den exakta adressen. Du kan hitta orphans med SEO-verktyg som Screaming Frog, men bäst är tänka på att sidor aldrig bör ”flyta fritt”.
Använd gärna breadcrumbs
Breadcrumbs eller brödsmulor är en smart navigeringshjälp som visas högst upp på varje sida så att användarna vet var de är i webbplatsens hierarki. Ett typexempel är:
Start > Kategori > Underkategori > Sida
Dessa är inte bara till fördel för användarna, utan också för sökmotorernas genomsökning. De kan också visas på sökresultatsidor via strukturerad data.
För att få maximal nytta är det dock viktigt att dina brödsmulor är statiska och inte ändrar sig beroende på vilken väg en användare tagit till en viss sida.
Prestanda och Core Web Vitals
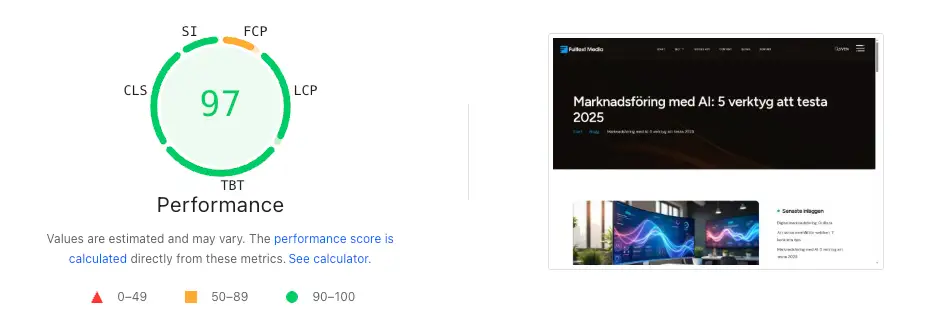
Laddningstid har blivit allt viktigare för teknisk SEO, inte minst sedan Google gick ut med att det används som en rankingfaktor. Även om det inte är en avgörande rankingfaktor i sig, ger långa laddtider en usel användarupplevelse.
Google har valt ut specifika mätvärden och kallar dessa Core Web Vitals.
LCP (Largest Contentful Paint) mäter hur snabbt sidans huvudsakliga innehåll ritas upp i visningsområdet. Det kan vara ett större visuellt element på din sida. LCP ska helst inträffa inom de första 2,5 sekunderna och allt över 4 sekunder anses dåligt.
INP (Interaction to Next Paint) ersatte det tidigare måttet FID (First Input Delay) förra året. INP mäter hur snabbt en webbplats svarar på en användares interaktion, exempelvis ett klick på en knapp. Ett INP under 200 millisekunder är att föredra, medan värden över 500 ms är desto sämre för användaupplevelsen. Måttet fokuserar på interaktivitet och hur snabbt resultatet visas för användaren efter en interaktion.
CLS (Cumulative Layout Shift) mäter sidans visuella stabilitet och hur mycket layouten förskjuts medan sidan laddas Här ska siffran vara under 0,1 och definitivt under 0,25.
Du kan snabbt få koll på dina värden med verktyget PageSpeed Insights.
Lösningar: Cachning och CDN
Caching är en teknik som innebär att kopior av data tillfälligt lagras i statiskt format så att de kan hämtas snabbare. Utan cache måste varje sida laddas från grunden vid varje besök, vilket ökar belastningen på servern och förlänger laddtiderna. Cache-lösningar innehåller funktioner för ”minifiering” av CSS- och JavaScript-filer, samt komprimeringstekniker.
En annan möjlighet är ett Content Delivery Network (CDN), vilket innebär att innehåll, framförallt mediafiler, kan hämtas från en extern server istället för att belasta den egna. CDN-nätverket kan vara geografiskt utspritt och leverera innehåll från den server som ligger närmast användaren. Det möjliggör också fler parallella överföringar, vilket ytterligare förbättrar hastigheten.
En cache-lösning bör alltid vara första steget för att snabba upp en webbplats, och om du använder WordPress finns många alternativ (tillägg) som är kostnadsfria.
Mobilanpassning
Google påbörjade en gradvis övergång till ”mobile-first”-indexering för snart tio år sedan. Det innebär att Google använder den mobila versionen av din webbplats för att indexer och rankar innehåll. Övergången är logisk eftersom merparten användare använder mobila enheter idag.
Du som driver en webbplats behöver därför säkerställa att:
- Mobilversionen har samma innehåll som desktopversionen.
- Strukturerade data och metadata är konsekvent mellan mobil och desktop.
- Navigering och länkar fungerar lika bra på mobilversionen.
De allra flesta CMS och tillhörande teman är utvecklade för att hantera alla skärmstorlekar idag, men vid större ändringar är det alltid en bra idé att jämföra mobil- och desktopversionerna.
Säkerhet: SSL-certifikat
Säkerhet i form av SSL-certifikat så att trafiken går över HTTPS är också i princip obligatoriskt, men inte heller något större bekymmer.
Certifikat kan du enkelt hämta gratis från Let’s Encrypt eller ZeroSSL om det mot förmodan inte är förinstallerat av ditt webbhotell. Vad som kan vara värt att kontrollera är att omdirigeringen från HTTP till HTTPS är tvingande och att du inte har blandat innehåll (HTTP-innehåll på HTTPS-sidor).
Duplicerat innehåll: canonical och noindex

Duplicerat innehåll är ett vanligt problem som påverkar många webbplatser. För användaren har det kanske mindre betydelse, men det ställer till det för sökmotorer som inte vet vilken version av en sida som ska indexeras och visas i sökresultaten. För Google är det nämligen inte intressant att visa två helt eller till stor del identiska sidor. Lösningarna stavas canonical-taggar och noindex-direktiv.
Hur canonical-taggen fungerar
Canonical-taggen är ett litet stycke HTML-kod som placeras i head-sektionen på en webbsida för att visa sökmotorern vilken URL som är den ursprungliga versionen. Man kan säga att den konsoliderar rankingsignaler till den angivna kanoniska URL:en. Koden ser ut så här:
<link rel="canonical" href="https://www.exempel.se/originalet/" />
Canonical-taggen endast en rekommendation, inte ett direktiv, vilket betyder att Google kan välja att ignorera den i vissa fall, men normalt sett respekteras taggen.
Det finns ett par varianter av taggen. En självrefererande canonical pekar på samma URL där den är placerad, vilket kan vara en bra försäkring mot oavsiktligt duplicerat innehåll samtidigt som den ger visst skydd för ditt originalinnehåll om någon kopierar din sida.
En extern canonical mot en annan URL, vilket är användbart när din webbplats är tillgänglig med både www och utan www, om du har sidor med URL-parametrar (t.ex. produktvarianter med ’?=storlek’), eller publicerar innehållet på externa plattformar.
När är noindex bättre?
Medan canonical-taggen hjälper sökmotorer att välja rätt version att visa, instruerar noindex-taggen sökmotorer att helt utesluta en sida från sökresultaten. Taggen ser ut så här:
<meta name="robots" content="noindex" />
Använd noindex främst när:
- Du absolut inte vill att sidan ska visas i sökresultaten
- Du har sidor med lågt eller inget SEO-värde (tacksidor, inloggningssidor etc.)
- Du vill att Google fortfarande ska crawla sidan men inte indexera den.
Undvik att kombinera noindex med blockering i robots.txt, eftersom sökmotorer då inte kan se noindex-taggen och sidan förblir indexerad (om den är indexerad sedan tidigare).
Däremot behöver det inte nödvändigtvis vara fel att använda både canonical och noindex tillsammans.
Verktyg för teknisk SEO-analys
Specialiserade SEO-verktyg som Ahrefs och Semrush är bra men alldeles för dyra för de flesta som bara driver en mindre webbplats.
Men det finns alternativ som hjälper dig att identifiera vanliga problem och förbättringsmöjligheter. Några av de mer självklara verktygen för din tekniska SEO-verktygslåda är:
Google Search Console
Google Search Console, tidigare känt som Webmaster Tools, är kostnadsfritt och ger insikter om hur Google ser din webbplats. Under rubriken ”Indexering” kan du se vilka sidor som har indexerats och varför vissa sidor eventuellt inte indexerats.
Du kan också använda URL-inspektionsverktyget för att detaljgranska enskilda sidor. Dessutom får du tillgång till en hel del intressant information om hur användare hittar till sajten.
PageSpeed Insights
PageSpeed Insights analyserar användarupplevelsen på både mobila enheter och datorer. Verktyget rapporterar i detalj vad som står ivägen för högre betyg och ger konkreta förslag på åtgärder.
Screaming Frog
Screaming Frog SEO Spider är ett kraftfullt verktyg som kan identifiera många tekniska SEO-problem. Gratisversionen är bland annat begränsad till 500 URL:er och saknar en del inställningsmöjligheter, men är ändå användbart.
Screaming Frog samlar in data om allt från URL-struktur till sidhierarkier och metainnehåll. Du kan också hitta trasiga länkar, omdirigeringar, duplicerat innehåll och brister i metadata. För SEO-migrering är Screaming Frog oumbärligt eftersom det effektivt kartlägger alla URL:er så att du kan implementera redirects.
Sammanfattning
Det går naturligtvis att gå på djupet med betydligt fler detaljer inom teknisk SEO, men nu har vi åtminstone fått med några av de viktigaste aspekterna av teknisk optimering – från en grundläggande förståelse av sökmotorernas arbetssätt till specifika implementeringar.
Teknisk SEO spelar tveklöst en viktig och i vissa fall helt avgörande roll som komplement till innehållsoptimering. En välstrukturerad webbplats med tydlig hierarki och snabba laddningstider skapar förutsättningar för både användare och sökmotorer att hitta och förstå ditt innehåll.